路科V0P30P33-覆盖率-代码覆盖率-功能覆盖率-从功能描述到覆盖率
覆盖率
- 随机测试比定向测试多了很多的可能性,但是需要考虑,什么时候结束验证呢?涉及到覆盖率指标的问题。
- 是否所有设计的功能在验证计划中都已经验证了?
- 是否代码中的某些部分从未执行过?
- 覆盖率 用来衡量设计验证完备性的通用词语;
- 覆盖率工具会在仿真过程中收集信息,然后进行后续处理并得到覆盖率报告。
- 通过覆盖率报告找到覆盖率之外的盲区,然后修改现有的测试用例或者创建新的测试来填补这些盲区;
- 一直迭代进行,直到覆盖率满足要求;
覆盖率反馈回路 :
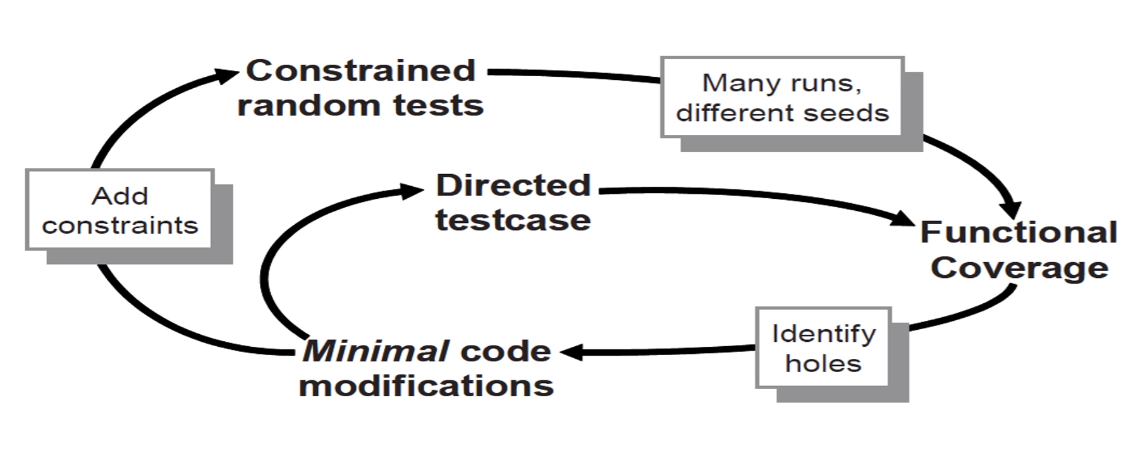
优化验证效率
- 通过覆盖率量化验证之后,可以在更复杂的情况下捕捉一些功能特性是否被覆盖:
- 在测试X特性时,Y特性是否同时被使能和测试?功能之间存在关联
- 是否可以精简已有的测试来加速仿真?并取得同样的覆盖率。冗余问题
- 观察覆盖率在达到一定数值之后,是否停滞不再上升?
- 覆盖率是用来衡量验证精度和完备性的数据指标;
- 可以告诉用户哪些结构在仿真时被触发,哪些没有;
覆盖率分类
- 代码覆盖率
- 功能覆盖率
- 断言覆盖率
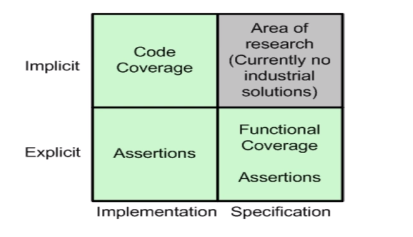
按照覆盖率生成的方法,分为两类:
- 隐形生成:
- 代码覆盖率,仿真工具可以自动分析RTL设计代码的执行结果得到代码覆盖率
- 显性生成:
- 断言覆盖率
- 功能覆盖率,需要依照功能描述去定义的覆盖率;
按照覆盖率溯源,分两类:
- 从功能描述而来:
- 功能覆盖率
- 从设计实现而来
- 代码覆盖率
- 断言覆盖率
代码覆盖率
- 包含未知错误的设计的问题在于它看起来很好,但是绝对不可能知道被验证的设计在功能上是完全正确的;
- 即使所有测试平台都成功仿真,但是只要有部分RTL代码未执行,都可能触发功能错误,因此需要代码覆盖率!
- 代码覆盖率的优势在于可以由仿真工具自动收集;
- 一般只关注设计的代码覆盖率,不关注测试平台的代码覆盖率;
行覆盖率(statement/line)
- 衡量源码哪些行被执行,哪些行没有;
- 每一行执行的最小次数也可以设置为一个指标;
- 代码覆盖率可以指出在缺乏激励的情况下,某些赋值的代码行没有被执行的情况,也可以指出一些漏洞影响或者无用代码的影响下,一些代码行也无法被执行的情况;
- 对于无用代码,即永远不会执行的代码,可以从覆盖率中过滤掉;
- 行覆盖率也叫做块覆盖率,块是在灾星单个语句时语句序列;
- 比如,只要if为true,就会执行名为acked的块,因此这个块的执行等同于四个单独语句的执行;
1 | if (data == 1'b1) begin: acked |
分支覆盖率(branch)
- 分支覆盖率是用来对条件语句
if/else case ?:,指出其执行的分支轨迹;
条件覆盖率(condition/expression)
- 条件覆盖率用来衡量一些布尔表达式的各个条件真伪判断的执行轨迹;
- 比如下面的if中两个条件是否各自衡量为true、false;
if (parity == ODD || parity == EVEN) begin
状态机覆盖率(FSM)
- 仿真工具可以自动识别状态机,因此在收集覆盖率时,可以将覆盖率状态的执行情况监测到;
- 可以反映到每个状态的进入次数、状态之间的跳转次数、以及多个状态的跳转顺序等;
- 因为FSM中的每个状态通常使用case语句中的选项进行编码,所以任务没有访问到的状态都可以通过未覆盖的语句清楚的识别到;
跳转覆盖率(toggle)
- 用来衡量寄存器跳转次数(0->1, 1->0);
- 一般项目会要求模块的端口实现至少一次1到0和一次0到1的跳转;,以保证模块的集成和模块之间的互动;
- 也有项目要求所有的寄存器和端口一样,满足跳转的最小次数;
- 端口跳转覆盖率常用来测试IP模块之间的基本连接性,比如检查一些输入端口是否没有连接,已经连接的端口的比特位数是否不匹配,一些已连接的输入是否被给定的固定值等;
代码覆盖率100%的含义
- 表明整个设计都已执行;
- 表示验证环境运行设计源码的彻底程度,但是没有提供有关验证组件的正确性和完整性的指示;
- 代码覆盖率应该用于帮助识别验证未执行的边界情况或者依赖于设计实现的特性;
- 对于未覆盖的场景,考虑更新和添加测试;
功能覆盖率
- 功能验证的目标,在于确定设计有关的功能描述是否都实现了;
- 可能存在的不期望的情况:
- 哪些功能没有被实现;
- 实现错误;
- 哪些没有要求的功能也实现了;
覆盖组(covergroup)
- 覆盖组和类相似,在一次定义之后可以多次例化;
- 覆盖组含有覆盖点(cover point)、选项(option)、形式参数(argument)和可选触发(trigger event);
- 一个覆盖组包含的一个或者多个数据点,都是在同一时间采集;
- 覆盖组可以定义在类里,也可以定义在模块或者程序中;
- 覆盖组可以采集任何可见变量,比如程序或模块变量、接口信号、或者设计中的任何信号;
- 在类中的覆盖组也可以采集类的成员变量;
- 覆盖组应该定义在适当的抽象层次上;
- 对任何事务的采样都必须等到数据被待测设计接收到以后;
- 一个类也可以包含多个覆盖组,每个覆盖组可以根据需要将它们使能或者禁止;
- 内部可以定义多个coverpoint,如果不在covergroup声明时指定采样事件,那么默认该覆盖组只能依赖于另一个手动采样函数sample();
1 | enum {red, green, blue} color; |
其他:
- 更多的时候,将覆盖组定义在类中,从而去覆盖类的成员变量;
- 在类中声明covergroup的方式称为嵌入式覆盖组声明,以下栗子声明一个覆盖组cov1和它的实例c1;
1 | class xyz; |
覆盖点(coverpoint)
- 一个covergroup可以包含一个或者多个coverpoint,一个coverpoint可以用来采样数据或者数据的变化;
- 一个coverpoint可以对应多个bin(仓);
- 这些bin可以显性指定,也可以隐性指定;
- coverpoint对数据的采样发生在covergroup采样的时候;
- 建议给不同的覆盖点不同的名字,以便于查看;
- 有名字的coverpoint可以用来进一步处理,比如在交叉覆盖率中使用某个coverpoint;
- 可以通过iff在一些情况下禁止coverpoint采集
1 | covergroup g4; |
仓:值覆盖
- 关键字bins可以用来将每个感兴趣的数值均对应一个独立的bin,或者将所有值对应到同一个bin;
- iff语句也可以用在bin的定义,表示条件为false,在采集该bin的时候,该bin的采样数目不会增长;
- bins除了可以覆盖数值,还可以覆盖数值的变化
value1 => value2;- 语法:
trans_item[* repeat_range] 3[* 5]表示3=>3=>3=>3=>33[* 3:5]表示(3=>3=>3),(3=>3=>3=>3)或者(3=>3=>3=>3=>3)
- 如果coverpoint没有指定任何bin,则sv会为他自动生成bin,遵循原则:
- 如果变量是枚举类型,则bin的数量是枚举类型的基数(所有枚举值得和);
- 如果变量是整型(位宽为M),则bin的类型是
2^M和auto_bin_max的较小值;
1 | bit [9:0] v_a; |
仓: 忽略类型和非法类型
ingnore_bins用来将其排除在有效统计的bin集合之外illegal_bins用来指出采样的数值为非法,如果illegal_bins被采样到,那么仿真会报错!
1 | covergroup cg23; |
交叉覆盖率 cross
- covergroup可以在两个或者更多的coverpoint或者变量之间定义交叉覆盖率;
- 在对a和b产生交叉覆盖率之前,系统会先为他们隐性生成对应的coverpoint和bin,每个coverpoint都有16个自动产生的bin;
- 两个coverpoint交叉产生256个bin;
- 注意:被声明为default、ignore、illegal的bin不会被交叉覆盖率计算;
- 交叉覆盖率只允许在同一个covergroup中定义的覆盖点参与运算。
1 | bit [3:0] a, b; |
从功能描述到覆盖率
概述


提取接口功能点

提取内部功能点


提取结构功能点

标记功能点

验证分层

优先级划分


从随机测试到功能覆盖率

覆盖率实现的考量

MCDT功能测试清单
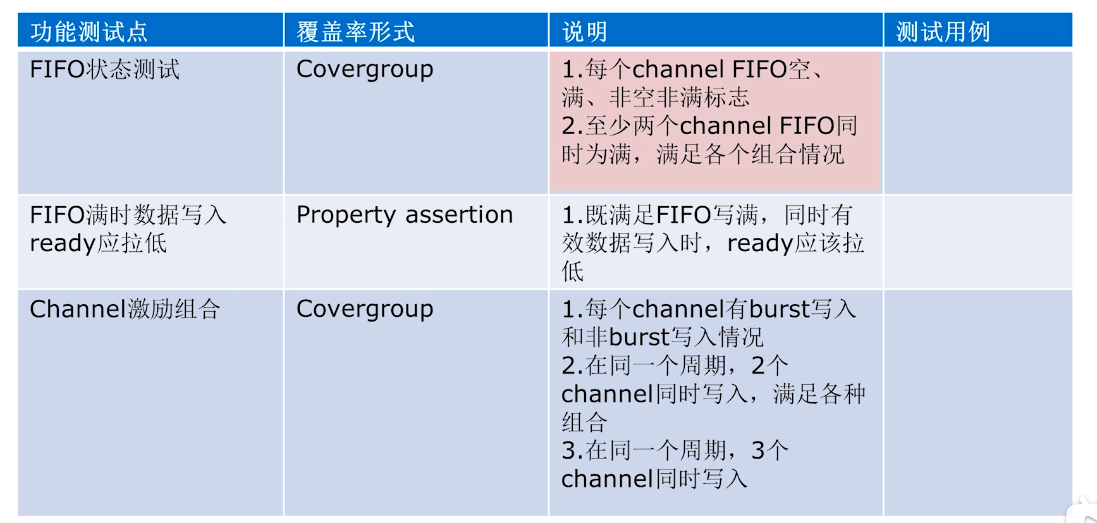
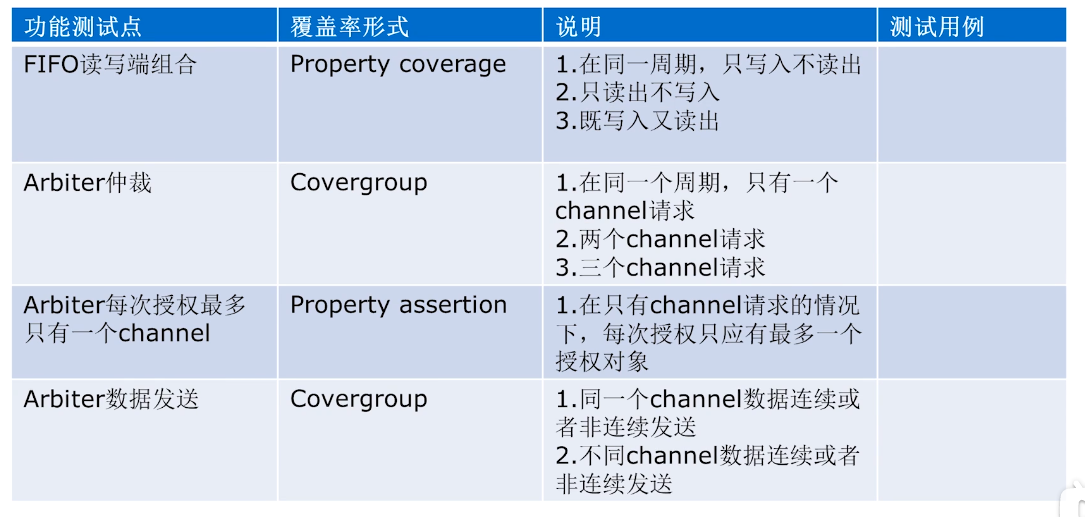
路科V0P30P33-覆盖率-代码覆盖率-功能覆盖率-从功能描述到覆盖率
https://dustofstars.github.io/IC验证/路科V0/路科v0p30p33-覆盖率-代码覆盖率-功能覆盖率-从功能描述到覆盖率/