路科V0P13P18SV数组-类-对象-包
数组操作
- 对于Verilog,数组用来做数据存储,比如
reg [15:0] RAM [0:4095]; //存储数组- 数组的索引名在数组右侧,左侧是每个数据的大小
非组合型(unpacked)数组
- 非组合型(unpacked) : SV将以上Verilog的声明方式称为非组合型声明,即数组中的成员之间的存储是互相独立的。
- 会消耗更多的存储空间,但是利于查找元素;
- SV对Verilog的非组合数组进行了保留,并且允许在声明时指定类型,包括
event logic bit byte int longint shortreal real等类型; - SV也保留了Verilog索引非组合型数组或切片的能力,利于数组和切片的拷贝和查找;
- 栗子:
int a1 [7:0][1023:0]; //非组合型数组int a2 [1:8][1023:0];a1 = a2; //拷贝整个数组a2[3] = a1[3]; //拷贝数组的某个片段 - 声明非组合型数组的方式:
- 指定元素个数 :
logic [31:0] data[1024]; //从右到左读,1024个32位 - 指定元素索引值的范围:
logic [31:0] data[0:1023];
- 指定元素个数 :
- 初始化: 对于非组合数组,需要用
'{}对每个维度分别赋值:int d [0:1][0:3] = '{'{7, 3, 0, 5}, '{1, 2, 3, 4}};
- 因为非组合型数组赋值繁琐,所以可以使用default关键字完成,
int a [0:7][0:1023] = '{default: 8' h55}; - 非组合型数组的数据成员和数组本身都可以为其赋值,
byte a [0:3][0:3]; a[1][0] = 8' h5; // 为单个元素赋值 a[3] = '{'hF, 'hA, 'hC, 'hE}; //给切片赋值 - 非组合型的赋值和拷贝,必须两边的维度完全一模一样;
- 非组合型数组和组合型数组之间,不能直接赋值!
组合型(packed)数组
- 组合型(packed) : SV将Verilog的向量作为组合型数组的声明方式
- 栗子:
wire [3:0] select; // 4比特的组合型数组reg [63:0] data; //64比特的组合型数组logic [3:0][7:0] data; // 2维组合型数组,注意,每个元素是data[0][7:0],索引在左侧,位宽在右侧,从左到右边读,4个8位,第二维4个,第一维8个 - 组合型数组更节省空间!规范了数据的存储方式,所以不需要关心编译器或者操作系统的区别;
- 组合型除了可以用数组的声明,还可以定义结构体的存储方式:
typedef struct { logic [7:0] crc; logic [63:0] data; } data_word; data_word [7:0] darray;- 组合型数组和其他数组片段也可以灵活选择,用来拷贝或者赋值:
logic [3:0][7:0] data; wire [31:0] out = data; wire sign = data[3][7]; wire[3:0] nib = data[0][3:0]; byte high_byte; assign high_byte = data[3]; //8bit数组片段 logic [15:0] word; assign word = data[1:0];
- 初始化 : 组合型数组的初始化,和向量的初始化一致,对所有元素统一赋值:
logic [3:0][7:0] a = 32'h0; //向量赋值logic [3:0][7:0] a = {16'hz, 16'h0}; //连接运算符logic [3:0][7:0] a = {16{2'b01}}; //复制运算符
- 组合型的赋值:
logic [1:0][1:0][7:0] a; a[1][1][0] = 1'b0; a = 32'hF1A3C5E7; //整个数组赋值 a[1][0][3:0] = 4'hF; //切片赋值 a[0] = 16' hFACE; // 给切片赋值 a = {16' bz, 16' b0}; //通过连接运算符赋值 - 组合型数组会被视为向量,所以两边操作数大小维度不同时也可以做赋值,非组合型不可以!
- 会将右侧的数据截取或者扩展,扩展时,是高位填充为0!
- 栗子:
sv中的foreach
- foreach: 循环,对一维或者多维数组进行循环索引,不需要指定数组的维度大小!
- 栗子:
int sum [1:8][1:3]; foreach(sum[i, j]) { sum[i][j] = i + j; } }; //对数组进行初始化 - foreach中的变量作用域只在循环中,且只读,无法修改;
- 栗子:
一些系统函数
$dimensions(array_name): 获取数组的维度大小;$left(array_name, dimension): 返回指定维度的最左索引值;- 栗子:
logic [1:2][7:0] word [0:3][4:1];最高的二维是4乘4,非组合,最低的二维为2乘8,组合型;$left(word, 1)返回的是0;$left(word, 2)返回的是4;$left(word, 3)返回的是1;$left(word, 4)返回的是7;
- 类似,还有
$right $low $high $size(array_name, dimension): 返回指定维度的尺寸大小;$increment(array_name, dimension): 如果指定维度的最左索引值大于最右索引值,返回1,否则-1;$bits(expression): 返回数组存储的比特数目;
数组类型
动态数组
- 动态数组在声明时,需要
[], 在编译时不会指定尺寸,在运行时才会确定; - 动态数组开始时为空,需要
new[]来分配空间;1
2
3
4
5
6
7
8
9
10
11
12int dyn[], d2[];
initial begin
dyn = new[5];
foreach (dyn[j]) dyn[j] = j;
d2 = dyn;
d2[0] = 5;
$display(dyn[0], d2[0]);
dyn = new[20](dyn); //分配20个整数并进行赋值
dyn = new[100]; //分配100个新的整数
dyn.delete(); // 删除所有元素
end - 内置方法
size()可以返回动态数组的大小。 delete()清空动态数组,使它尺寸变为0;- 动态数组在声明时也可以初始化
1
bit [7:0] mask[] = '{8'b0000_0000, 8'b0000_0001, 8'b0000_0010, 8'b0000_0011, 8'b0000_0100, 8'b0000_0101, 8'b0000_0110, 8'b0000_0111};
队列
- sv引入了队列类型,它结合了数组和链表;
- 可以在队列的任何位置添加或者删除数据成员;
- 也可以索引访问队列的任何成员;
- 通过
[$]声明队列, 队列的索引值从0到$; - 可以通过队列的内建方法
push_back(val)、push_front(val)、pop_back()、pop_front()来操作; - 在指定位置插入成员,可以使用
insert(val, pos); - 可以使用
delete(pos)删除指定位置的元素; - 可以使用
{}连接运算符对队列进行拼接;
栗子:
1 | int j = 1, |
关联数组
- 处理器在访问存储时是随机或者散乱的,所有测试中,处理器也许只会访问几百个存储地址,其他的初始化为0,浪费了仿真时的存储空间。
- SV中的关联数组,存放散列的数据成员,关联数组的索引类型,除了为整型之外还可以是字符串或者其他类型,而且关联数组存储的数据成员也可以是任意类型!
栗子:
1 | byte assoc[byte], idx = 1; |
栗子2:输入文件
1 | int switch[string], min_address, max_address, i, file; |
以上三种数组:动态数组、队列、关联数组,都是大小可变的数组,下面,讨论他们的公共方法!
缩减方法
- 缩减方法指的是把一个数组缩减为一个值
- 最常见的是sum对数组元素求和;
- 还有and、or、or(异或)
栗子:
1 | byte b[$] = {1,2,3,4}; |
定位方法
- 对于非合并数组,可以使用数组定位方法,返回值是一个队列,而不是数据成员;
- 包括min、max、unique
d.find_ with(expression)
栗子:
1 | int f[6] = '{1,2,2,3,4,5,6}; //定长数组 |
排序方法
- 通过排序方法,改变数组中元素的顺序,对他们进行正向、逆向、或者乱序的排序;
- reverse : 反转
- sort : 从小到大
- rsort
- shuffle
类的封装
- 类是一种可以包含数据和方法(function、task)的类型;
- 例如一个数据包,可以定义为一个类,类中可以包含指令、地址、队列ID、时间戳和数据等成员;
类的概述
- 软件的类和硬件的module都可以理解为容器,但是类对于构建验证环境更加灵活!
- OOP可以使用户能够创建复杂的数据类型,并且将他们和能够使用这些数据类型的程序结合在一起;
- 用户可以在更加抽象的层次建立测试平台和系统级模型,通过调用函数来执行一个动作而不是简单的改变信号的电平;
- 验证环境的stimulator、monitor、checker以及其他验证组件都可以按照OOP方式来构建;
- SV在类的定义中,只需要构建函数new,不需要定义析构函数
- new函数的作用:
- 例化对象时开辟内存空间;
- 对对象的成员变量初始化;
- 执行完之后,返回对象实例的句柄;
1 | class Packet: |
class和struct的区别:
- 结构体可以包含数据成员,但是不能有成员方法,也无法进行例化;
static和其他:
- 句柄:指向对象的指针;
- 原型:程序的声明部分,包括程序名、返回类型和参数列表;
- 类在定义时,如果没有构建函数,系统会自动定义一个空的构建函数;
- 对象需要先声明再例化,或者同时进行;
- 类的成员变量和方法默认都是动态的,即每个对象的变量和方法都会相应的开辟新的内存空间;
- 如果多个对象要共享一个成员变量或者方法,可以使用static关键字修饰!
- 对于静态成员变量,在类没有例化的时候,就可以访问到,使用
p.val或者Packet::val- 注意:静态方法不能访问动态成员变量,否则报错!
this
- this是用来明确索引当前所在对象的成员(变量、参数、方法);
- this只能用在类的非静态成员方法、约束、和覆盖中。
- this的使用可以明确所指向变量的作用域,避免变量指向不清晰的问题;
1 | class Demo: |
对象拷贝
句柄的传递
- 区分类和对象之后,还要区分对象和句柄。对象创建之后,在内存的位置就不会改变了,但是指向该空间的句柄可以有不止一个;
1 | Transaction t1, t2; //声明句柄 |
赋值和拷贝
- 声明变量和创建对象是两个过程
Packet p1; p1 = new();
- 如果将p1赋值给p2,那么还是只有一个对象,但是有两个句柄;
- p1和p2指向不同的对象,在创建p2时,从p1拷贝其成员变量,这种方式称为浅拷贝
栗子:
1 | Packet p1, p2; |
- 如果两个句柄指向同一个对象,那么一个句柄修改了成员变量,另一个也会受影响;
- 如果想要拷贝一个对象,则可以使用
p2 = new p1;的形式;
深入理解浅拷贝
栗子:
1 | class rgb: |
- SV中,对象的拷贝,只针对成员变量;
- 如果对象中还有别的句柄,那么在new拷贝对象时,只能对color句柄拷贝,而不会对它指向的对象再做拷贝,称为浅拷贝!
- pixel dot2 = new dot; //浅拷贝
- pixel dot3 = dot.copy(); //深拷贝
- SV的new只能浅拷贝,需要深拷贝时,需要用户自己定义copy函数!
- 类的成员在默认情况下,是公共属性的,表示对于类自身和外部都可以访问该成员变量和成员函数;
- 可以隐藏和封装,限制外部访问;
- local:只有该类可以访问该成员,子类和外部都不能访问;
- protected:该类和子类都可以访问该成员,但是外部不能访问;
- 通过接口函数完成local的修改,开发者只需要维护接口函数即可;
栗子:
1 | class Packet: |
类的继承
继承和子类
- 比如,在Packet类扩展一个新的类LinkPacket;
- 通过extends关键字,LinkedPacket继承父类Packet,所有的方法和成员变量;所以,LinkedPacket对象中也包含Packet类的成员;
- 所以,父类的句柄也可以指向子类的对象!
- 如果子类中声明了与父类同名的成员,那么子类对他的同名成员的访问都指向子类,父类的成员被隐藏了! —> 成员覆盖!
1 | class LinkPacket extends Packet; |
成员覆盖的栗子:
1 | class Packet; |
super
super: 用来访问当前对象的父类的成员;- 尤其当子类的成员和父类的成员同名时,需要使用super来指定访问父类的成员,而不是默认的子类成员;
super的栗子:
1 | class Packet; |
验证环境中的案例
已经有了generator和driver两个组件,第一个单纯产生激励数据,第二个单纯使用激励数据发送时序激励;
这种单一职责划分,使得各个组件的任务十分明确;
如果要将数据发送到DUT,需要以下的基本元素和数据的处理方法,我们把他们封装在Transaction类中;
如果为了测试DUT的稳定性,需要加入一些错误的数据测试DUT的反馈,但是又想尽量复用原有的环境和各种已经定义好的类,则可以使用继承的方法,创建一个类BadTr
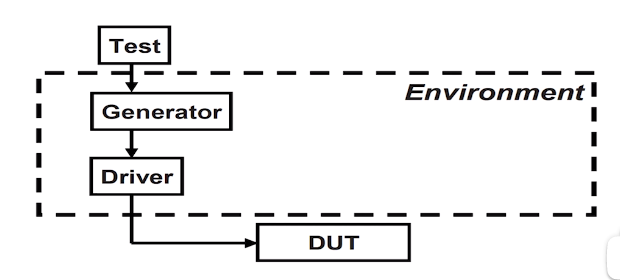
1 | class Transaction; |
包的使用
两个模块同名会出现错误或者后面的覆盖了前面的,
- 大型项目中,容易出现模块重名;
- 对于重名的硬件模块,可以将他们放到不同编译的库中;
- 对于重名的软件类、方法,可以放入不同的包中;
- 使用不同的验证IP时,不知道是否会有重名的类,所以使用包package将关联的方法和类放入同一个逻辑集合;
- package还可以在多个模块或者类之间共享用户定义的类型;
- 用户自定义的类型,比如类、方法、变量、结构体、枚举都可以在
package .. endpackage中定义; - 在module、class、interface中,都可以使用包中定义或者声明的内容;
- 通过域索引符,
::可以直接使用definitions::parameter
- 可以通过import指定索引一些需要的包中定义的类型到指定的域中,或者使用
*把包中的类型都导出:
1 | module M; |
- 建议在不同包中的类名,命名时要加上包的前缀。
1 | package definitions; |
包和库的区分
- package容器可以对类型做一个隔离作用;
- package的意义是把软件中的类、方法、变量封装在各自不同的域中,与全局域做好隔离;
- lib库是编译的产物,硬件的module、interface、program都会编译到库中,如果不指定编译库的话,会编译到默认的库中;
- lib库可以容纳硬件类型,也能容纳软件类型(类、方法和包等)
- package包只能容纳软件类型,比如类、方法和参数;
路科V0P13P18SV数组-类-对象-包
https://dustofstars.github.io/IC验证/路科V0/路科v0p13p18sv数组-类-对象-包/